It’s time to go beyond Scrum and Kanban and explore what drives a culture of effectiveness and impact at Tipalti.
In this post, I’ll lay out seven alternative practices to Scrum and Kanban that any development team can easily integrate into their workflows, regardless of their agile methodology of choice, helping to ensure an effective and healthy development process.
As the title suggests, Scrum and Kanban are the two primary agile methodologies currently dominating the software development landscape.
Both methodologies have been around for some time and have significantly helped shape the reality of modern software development. However, I feel that while these methodologies are effective, these approaches can leave gaps in creating a more efficient software development lifecycle. The seven practices aim to fill those gaps.
Scrum or Kanban?
Over the years, we’ve had the opportunity to adopt both Scrum and Kanban within Tipalti. Instead of strictly adhering to one methodology, we view them both more as tools in a larger toolkit of practices and approaches to software development.
We understand that different teams at different product maturity levels and business needs require different approaches. The software development teams at Tipalti have the autonomy and flexibility to periodically assess and select the most appropriate tool for the job, whether Scrum, Kanban, or any other agile development methodology.
However, to ensure the effectiveness of all teams, we’ve identified seven methodology-agnostic practices that have proved crucial for an efficient development process. We encourage our teams to practice all of them on top of their chosen methodology.
So, what are these seven practices?
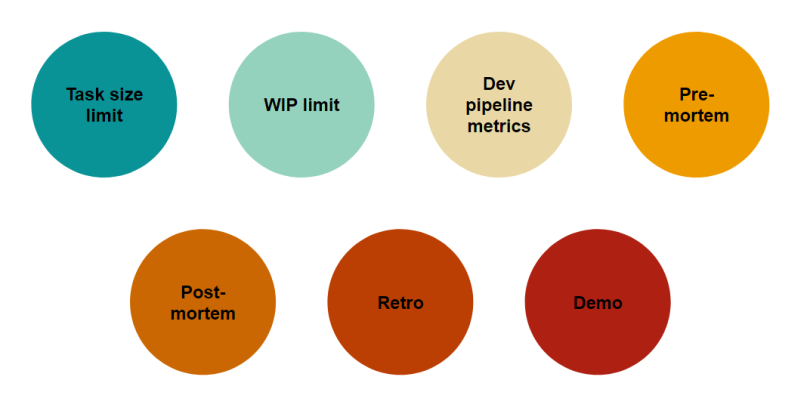
The Seven Practices
1. Task size limit
What’s the Goal: To ensure each development task has a size limit.
Why it’s important: Smaller tasks offer countless benefits: they allow for more flexibility in planning, help encourage continuous delivery, are easier to estimate, are easier to test, and increase motivation—it’s more fun to deliver frequently!
How we’ve implemented it: We set a guideline to limit each development task to five business days, triggering an automatic notification when a task exceeds ten business days in development status.
2. Work in progress (WIP) limit
What’s the goal: For teams to not be working on too many tasks at the same time.
Why it’s important: By ensuring we don’t have too many active tasks on our teams’ plates, we can avoid tasks piling up and clogging the development pipeline.
If a team brings in more tasks from the backlog than they are completing, it signals a bottleneck. This red flag doesn’t tell us exactly what the issue is, but it’s enough to make us pause and reevaluate.
How we’ve implemented it: Our development pipeline in Jira highlights the board in red when the number of tasks is more than twice the number of developers with an In-Development status, signaling there’s a bottleneck we need to address.
3. Measuring the development pipeline
What’s the goal: To measure key metrics like throughput, cycle times, and task type allocation (how much have we worked on each type of task).
Why it’s important: Having visibility into these metrics allows the team to better identify potential issues or opportunities.
How we’ve implemented it: At Tipalti, we’ve built dashboards in our BI platform on top of our Jira data. This required creating a custom data pipeline. Today, there is a variety of platforms available on the market that can provide this functionality.
4. Pre-mortem
What’s the goal: To conduct a pre-mortem session to help mitigate and prevent risks before going live.
Why it’s important: This might be the most valuable practice on this list and one that is super simple to implement since it can both help you prevent production issues and, in case they do happen, resolve them much faster.
How we’ve implemented it: Before we go live with a big or important deliverable, the team gets together, and we ask ourselves four simple questions:
- When/if this thing breaks, what could have gone wrong?
- How fast can we learn there’s an issue?
- How can we quickly identify the root cause of the problem?
- What could we have done to prevent this from happening in the first place?
It is incredible how effective brainstorming these simple questions can be, helping us save countless—and painful—manhours by implementing mitigations that came up during a pre-mortem session.
5. Post-mortem
What’s the goal: After an incident or when something goes wrong, we conduct a post-mortem session. This lets us transform the lessons learned from the incident into action items to help prevent it from happening again.
Why it’s important: Unfortunately, production incidents are an unavoidable reality. Conducting a quality post-mortem is the best way to uncover the root causes of what happened and help implement action items to prevent the next incident.
How we’ve implemented it: Following an incident, we conduct a session with all relevant stakeholders. It’s important that the session be blameless and that everyone is focused on describing and understanding what happened, analyzing the root causes (I highly recommend using the Five Whys method), and brainstorming follow-up action items.
6. Retrospective
What’s the goal: To analyze our performance as a team and find new ways to improve. The primary focus is on our processes and the software development lifecycle.
Why it’s important: By being mindful and honest about how we all performed as a team, we can continuously find ways to improve and adapt to the current reality.
How we’ve implemented it: This would be the standard retrospective session within the Scrum methodology. For teams not practicing Scrum, I recommend having a retrospective session at least once a month, with the format being a simple roundtable of asking the team:
- What worked well?
- What could be improved?
- What are the action items we are taking away from the session?
7. Demo
What’s the goal: To share your achievements with the team via a short demo.
Why it’s important: Demos are not just a great way to recognize the team by celebrating their achievements but also an opportunity to receive feedback and increase transparency across the organization.
How we’ve implemented it: Similarly to retrospectives, demos are a part of the Scrum methodology. For other methodologies, we usually conduct a demo when we reach a major milestone.
Taking Agile Beyond Industry Norms
Looking at the connecting thread between all of these practices, you’ll notice they are all about continuous improvement.
Whether you’re part of an early startup striving for product-market fit or a large enterprise looking to increase efficiency, implementing these seven practices will not only help your team fill the gaps created by traditional methodologies but will also help you achieve a healthier software development environment.
Do you know any additional practices we should have included here? Let us know in the comments below.